


The Impact of Relevant Context Position and Context Size on LLM Performance
The Impact of Relevant Context Position and Context Size on LLM Performance
Optimal performance is achieved when relevant information is at the start or end of the context, and performance decreases with longer contexts and when relevant information is in the middle.

Introduction
In the realm of artificial intelligence, Large Language Models (LLMs) have been making significant strides, demonstrating impressive capabilities in understanding and generating human-like text. However, their performance is not solely dependent on their architecture or training data. A crucial yet often overlooked factor is the context provided to these models, specifically its position and size in prompts. This article delves into the influence of relevant context position and size in prompts on LLM performance. The insights are drawn from a recent Research paper https://arxiv.org/pdf/2307.03172.pdf
"Lost in the Middle: How Language Models Use Long Contexts" by Nelson F. Liu et al. from Stanford University, University of California, Berkeley and Samaya AI
Background
Language models are vital and flexible elements in user-facing technologies like conversational interfaces, search tools, and collaborative writing platforms. They perform tasks through prompting, where task instructions and data are formatted into a text context, and the model generates a text completion. These contexts can contain thousands of tokens, especially when models process lengthy inputs like legal documents or conversation histories, or when supplemented with external information. The way how these lengthy documents are passed to LLM prompts can be found in my previous article.

Context Position and LLM Performance
The study found a distinctive U-shaped performance curve when the position of the relevant information is varied. LLM performance is highest when relevant information occurs at the very beginning or end of its input context, and performance significantly degrades when models must access and use information in the middle of their input context. This suggests that the position of the relevant context in the prompt is critical for optimal LLM performance.
The following graph shows that GPT 3.5 degrades when the position of relevant context moves away from the beginning. It also degrades below GPT 3.5 closed-book (No context provided) in the middle.
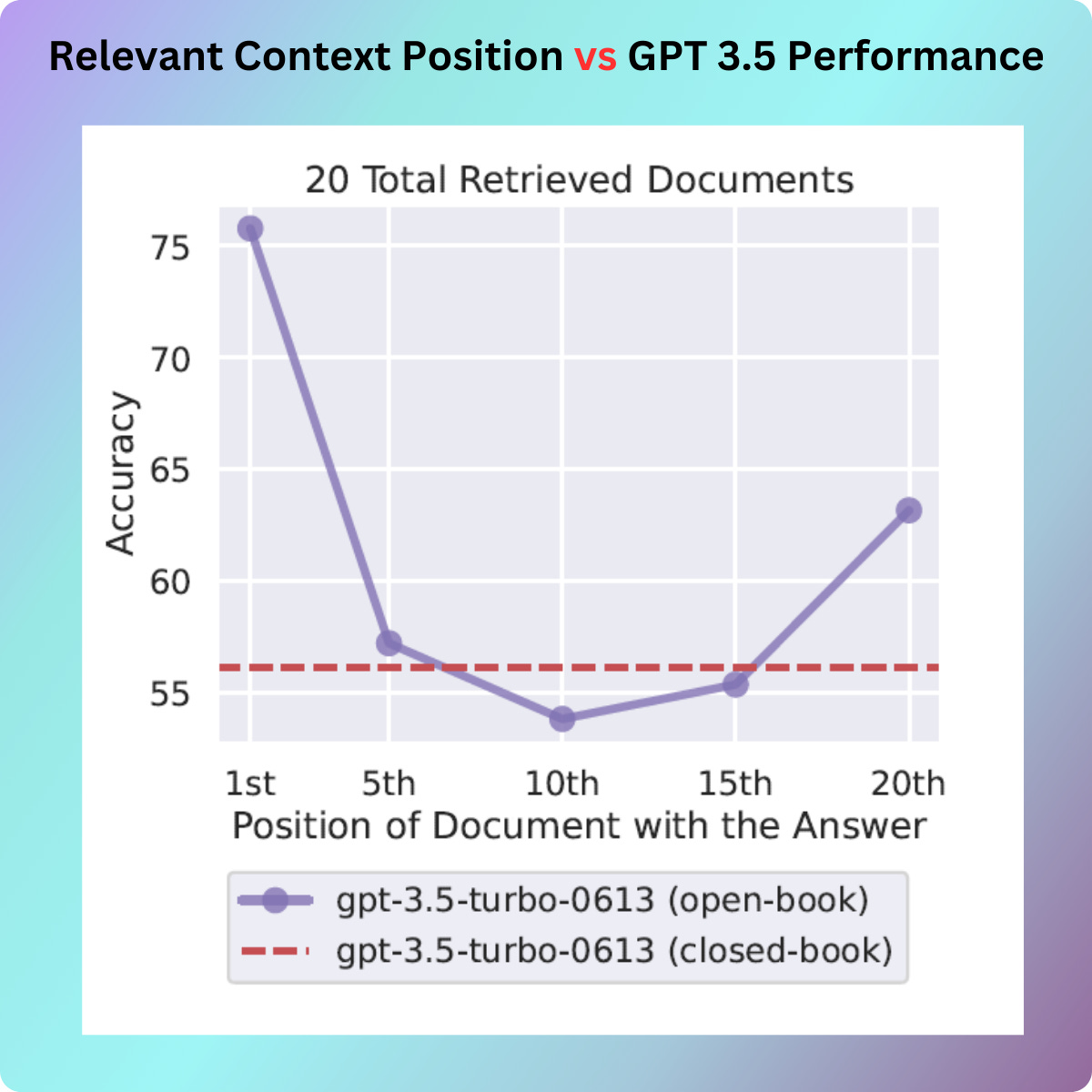
The same behaviour is exhibited across all models including GPT-4, Claude, MPT. GPT-4 outperformed all other language models in terms of absolute performance. However, it still exhibited a U-shaped performance curve, with the highest performance when the relevant information was located at the beginning or end of the context. The performance declined when the model had to utilize information situated in the middle of its input context.
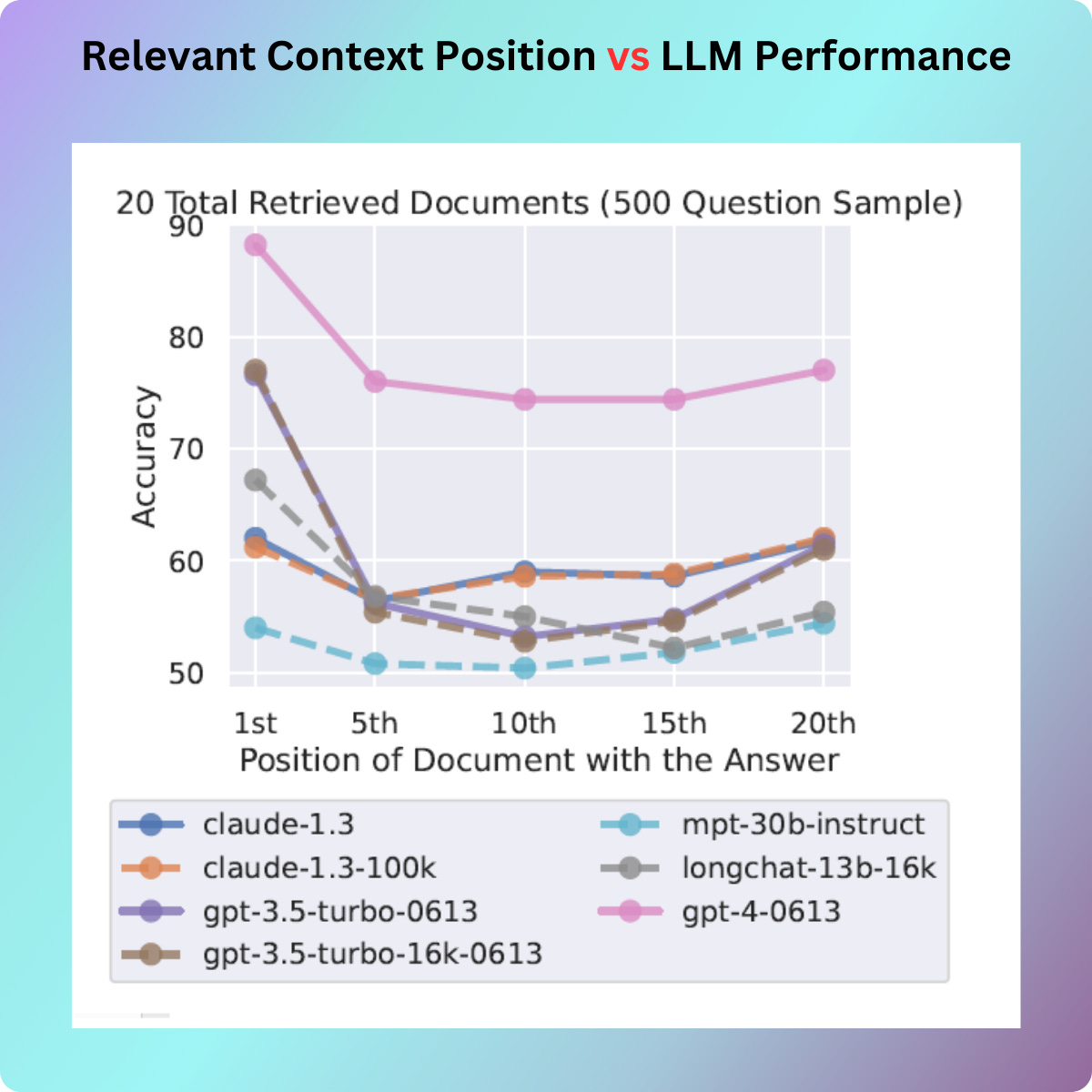
Context Size and LLM Performance
The size of the context also plays a significant role. The study found that as the input context grows longer, the performance of LLMs substantially decreases, even for models explicitly designed for long-context tasks. This indicates that while providing more information can be beneficial, there is a trade-off. Increasing the amount of content that the model must reason over can lead to a decrease in performance.

More Insights
The same U-shaped performance pattern is noticed in both two types of tasks - multi-document question answering and key-value retrieval.
The encoder-decoder models(Flan T5) unlike decoder-only models(GPT, Claude), are relatively stable when the position of relevant information changes within their input context.
The query-aware contextualization potentially help improve performance. It is a technique where the model is aware of the query or task at hand while processing the input context.
Models with longer context windows, like GPT-3.5-Turbo (16K), don't necessarily perform better than their counterparts GPT-3.5-Turbo (8K) when handling the same input context.
The instruction tuned model(MPT-30B-Instruct) and their base model counterpart (MPT-30B) exhibit same behaviour.
Improving document reranking (moving important information to the start of the context) or truncating the ranked list (returning fewer documents when needed) could enhance how language models use retrieved context.
Conclusion
The findings from the study provide valuable insights into the design and utilization of prompts for LLMs. It underscores the importance of carefully considering the position and size of the relevant context in prompts to optimize LLM performance. While more research is needed to fully understand these dynamics, these findings offer a starting point for developing more effective strategies for using LLMs.
The study also introduces new evaluation protocols for future long-context models and encourages further research in this area. As we continue to push the boundaries of what LLMs can do, understanding the nuances of how they use their input context will be crucial for unlocking their full potential.