


Retrieval Augmented Generation (RAG): Bridging Domain Specific Knowledge Gaps in LLM
Retrieval Augmented Generation (RAG): Bridging Domain Specific Knowledge Gaps in LLM
Retrieval Augmented Generation (RAG) enhances LLMs by fusing retrieval-based and generative techniques, addressing LLM limitations like static knowledge, hallucinating, not citing source.

Introduction
In the ever-evolving realm of artificial intelligence, Large Language Models (LLMs) have emerged as front-runners, propelling various applications to new heights. However, they aren't without their challenges especially when LLM requires Domain specific knowledge in order to perform its task. Enter Retrieval Augmented Generation (RAG) - a transformative approach addressing the intrinsic limitations of LLMs. Let’s delve deeper into what is RAG and why it is deemed indispensable for mitigating prevalent LLM issues in domain specific knowledge driven applications.
Retrieval Augmented Generation (RAG)
At its core, RAG is a fusion of two primary techniques: retrieval-based and generative-based AI models. Retrieval-based systems are adept at sourcing information from pre-existing data, be it from online articles, databases, or platforms like Wikipedia. On the other hand, generative models excel at crafting original, context-aware responses. RAG combines the best of both worlds. First, it leverages a retrieval system to fetch relevant information from existing knowledge bases. Then, a generative model processes this information, synthesizing it into a coherent, human-like response. This technique ensures responses are not only unique and context-aware but also anchored in accurate, pre-existing knowledge.
For example, Imagine LLMs as highly knowledgeable scholars who've last updated their knowledge a few years ago. While they have a vast understanding, they might be unaware of recent events or specific data outside their training. Retrieval systems acts like a helper, who quickly fetches the latest books, articles, or specific documents to update this scholar with current data or contextually relevant information. So, when you ask a complex, recent, or domain-specific question, instead of the scholar (LLM) potentially giving an outdated or generalized answer, with Retrieval system’s help, they provide a more informed, up-to-date response, often even telling you which book (source) they got the information from. In essence, RAG ensures that our AI "scholar" remains current, precise, and trustworthy.
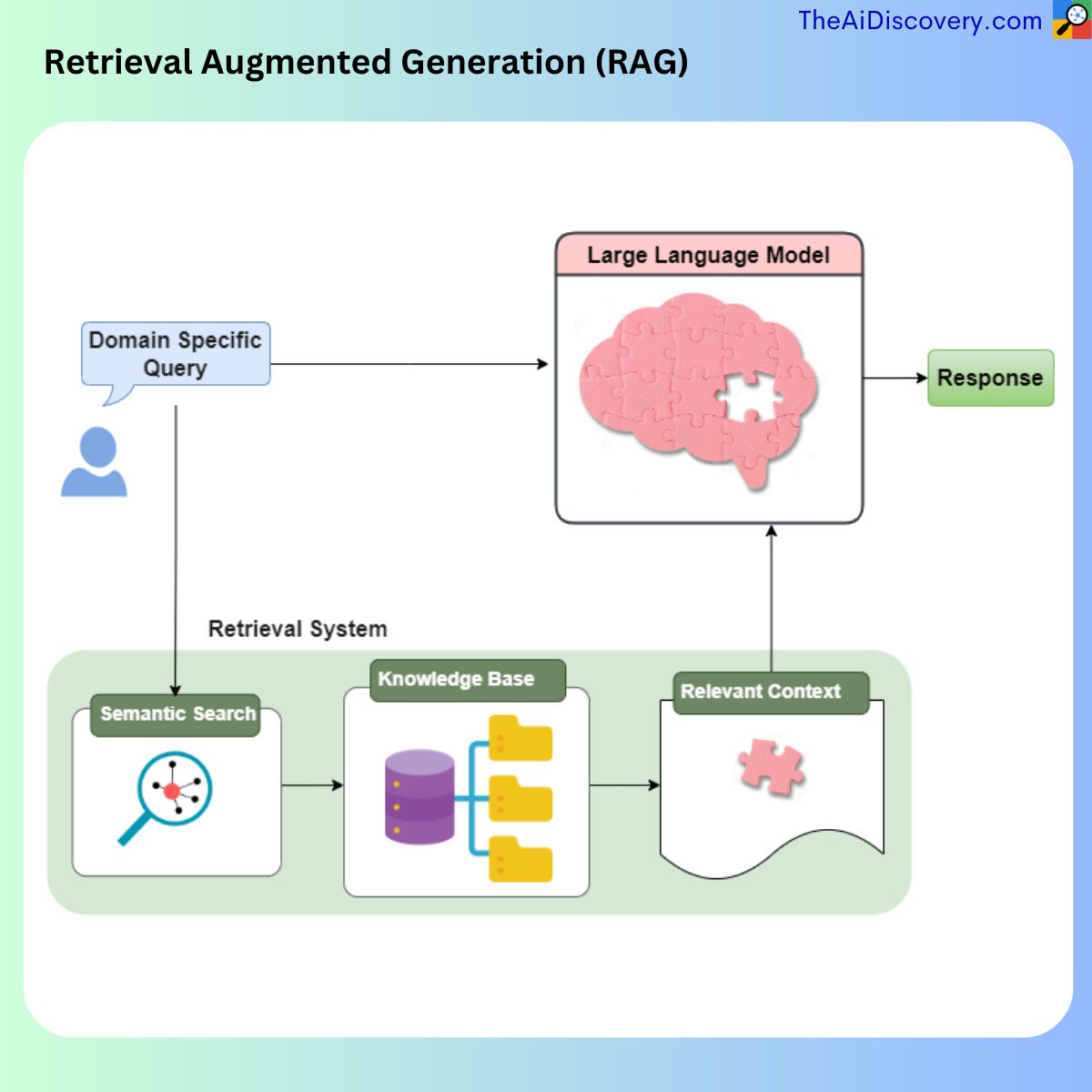
Bridging Domain Specific Knowledge Gaps
1. Updating Static Knowledge
One of the notable challenges with LLMs is that they're trained on data up to a certain point in time, making them “stuck” in that temporal window. This means that any advancements, new data, or real-time events post that period aren’t recognized by these models. RAG provides a solution to this limitation.
By integrating retrieval mechanisms, RAG can source up-to-date information from various databases, keeping the model's knowledge refreshed and enabling it to be more contemporaneously aware.
Essentially, while LLMs might be locked in the past, RAG brings them into the present.
2. Reducing Hallucination
When it comes to domain-specific or company-proprietary information, LLMs can often misstep, or 'hallucinate'. This is because they aren't natively equipped to access private databases or internal repositories. RAG, with its retrieval mechanism, can bridge this gap. By fetching relevant data from private sources, it can equip LLMs to answer specific questions with greater accuracy, significantly reducing the likelihood of generating irrelevant or incorrect responses.
3. Enhancing Transparency and Auditability
In the age of misinformation, source credibility is paramount. While traditional LLMs generate responses based on their training data, they don’t inherently cite the origins of their information. RAG introduces a game-changing feature here.
It allows the Generative AI to not only retrieve information but also cite its sources.
This feature provides a twofold benefit: enhancing the trustworthiness of the information and improving the model's auditability. Users can trace back the sources, ensuring that the generated content is anchored in credible data.
4. Overcoming the Context-Window Limitation
Foundational LLMs have a predefined limit to the number of tokens they can process at once, termed as the context-window. This is a serious limitation as domain specific knowledge corpus can be vast such that it will cross the token limit of foundational models. With Retrieval Augmentation, RAG can circumvent this restriction. It does so by retrieving only relevant context from expansive document collections, giving the model a short but rich context. As a result, outputs become more informed, detailed, and contextually richer.
5. Efficient Training on Vast Domain Knowledge Corpus
Training robust AI models can be resource-intensive, both in terms of data and computational power. Also most of the foundational models like GPT-4, PaLM2, Cohere do not allow to fine tune the base model. RAG offers a more economical approach. Instead of the conventional fine-tuning required for LLMs, RAG demands only the indexing of a knowledge base. This streamlined process not only reduces the computational footprint but also ensures performance comparable to extensively trained models. For organizations or researchers operating within budget constraints or with limited infrastructure, this aspect of RAG is a boon, offering state-of-the-art capabilities without the hefty resource commitments.
Use Cases of RAG in Various Domains
Healthcare: Physicians and medical researchers can utilize RAG-enhanced LLMs to pull from the latest medical journals or patient databases, ensuring accurate diagnoses, treatment suggestions, or research findings that include the latest advancements.
Legal: For lawyers and paralegals, sifting through vast legal documents and case laws can be daunting. RAG can quickly retrieve relevant legal statutes or precedents, making legal research more efficient and comprehensive.
Education: Educators and students can harness RAG-powered LLMs for personalized learning. Whether it's a deep dive into a historical event or understanding complex scientific phenomena, RAG ensures the information provided is both broad and up-to-date.
Finance: Financial analysts could use RAG systems to pull real-time data from multiple reports, news sources, and databases, helping them make more informed investment decisions.
Technical Support: Beyond customer service, RAG can be employed in technical support scenarios, pulling troubleshooting guides or forum solutions relevant to a user's specific problem.
Conclusion
In conclusion, Retrieval Augmented Generation is revolutionizing the way we use and trust Large Language Models. By bridging the knowledge gaps and enhancing domain-specific expertise, RAG is set to make LLMs an even more invaluable tool across numerous industries and sectors.